使用 nginx-openid-connect 模块 让nginx作为网关登录
· 3 min read

timger
什么是 openid
详细
openid 配置部分
什么是 .well-known/jwks
.well-known/jwks 是一个标准的 URI 路径,用于在 Web 服务器上公开 JSON Web Key Set(JWKS),以便其他应用程序可以使用它们来验证令牌的签名。
JSON Web Key Set(JWKS)是一种包含公钥或证书的 JSON 格式文件,用于在 OAuth 2.0 和 OpenID Connect 等身份验证和授权协议中进行令牌签名验证。通过公开 JWKS,应用程序可以获取到用于验证签名的公钥,从而验证来自认证服务器签发的令牌的合法性。
在 OAuth 2.0 和 OpenID Connect 中,认证服务器通常会使用非对称加密算法生成令牌的签名,并将公钥或证书存储在 JWKS 中。其他应用程序可以通过获取 JWKS 中的公钥来验证令牌的签名,确保令牌的真实性和完整性。
因此,当一个应用程序需要验证来自认证服务器签发的令牌时,它可以通过访问 .well-known/jwks 路径来获取 JWKS,并使用其中的公钥来验证令牌的签名。这有助于确保令牌的安全性和有效性。
配置
启动js支持
需要 ngx_http_js_module.so
在开始在研究
- https://github.com/nginx/njs
- https://pkgs.alpinelinux.org/package/edge/main/ppc64le/nginx-mod-http-js 和 https://casdoor.org/zh/docs/integration/C++/Nginx/ https://casdoor.org/zh/docs/integration/C++/NginxCommunityVersion
感觉纯nginx 比较复杂, 要么需要 nginx plus 要么配置负载
换 https://github.com/zmartzone/lua-resty-openidc 看看
RUN luarocks install lua-resty-openidc
RUN luarocks install lua-resty-http
RUN luarocks install lua-resty-session
RUN luarocks install lua-resty-jwt
安装目录
#15 [11/20] RUN luarocks list
#15 0.208
#15 0.209 Rocks installed for Lua 5.1
#15 0.209 ---------------------------
#15 0.209
#15 0.209 lua-ffi-zlib
#15 0.209 0.6-0 (installed) - /usr/local/openresty/luajit/lib/luarocks/rocks-5.1
#15 0.209
#15 0.209 lua-resty-auto-ssl
#15 0.209 0.13.1-1 (installed) - /usr/local/openresty/luajit/lib/luarocks/rocks-5.1
#15 0.209
#15 0.209 lua-resty-http
#15 0.209 0.17.2-0 (installed) - /usr/local/openresty/luajit/lib/luarocks/rocks-5.1
#15 0.209
#15 0.209 lua-resty-jwt
#15 0.209 0.2.3-0 (installed) - /usr/local/openresty/luajit/lib/luarocks/rocks-5.1
#15 0.209
#15 0.209 lua-resty-openidc
#15 0.209 1.7.6-3 (installed) - /usr/local/openresty/luajit/lib/luarocks/rocks-5.1
#15 0.209
#15 0.209 lua-resty-openssl
#15 0.209 1.5.1-1 (installed) - /usr/local/openresty/luajit/lib/luarocks/rocks-5.1
#15 0.209
#15 0.209 lua-resty-session
#15 0.209 4.0.5-1 (installed) - /usr/local/openresty/luajit/lib/luarocks/rocks-5.1
#15 0.209 3.10-1 (installed) - /usr/local/openresty/luajit/lib/luarocks/rocks-5.1
#15 0.209
#15 0.209 shell-games
#15 0.209 1.1.0-1 (installed) - /usr/local/openresty/luajit/lib/luarocks/rocks-5.1
#15 0.209
#15 DONE 0.2s
其他
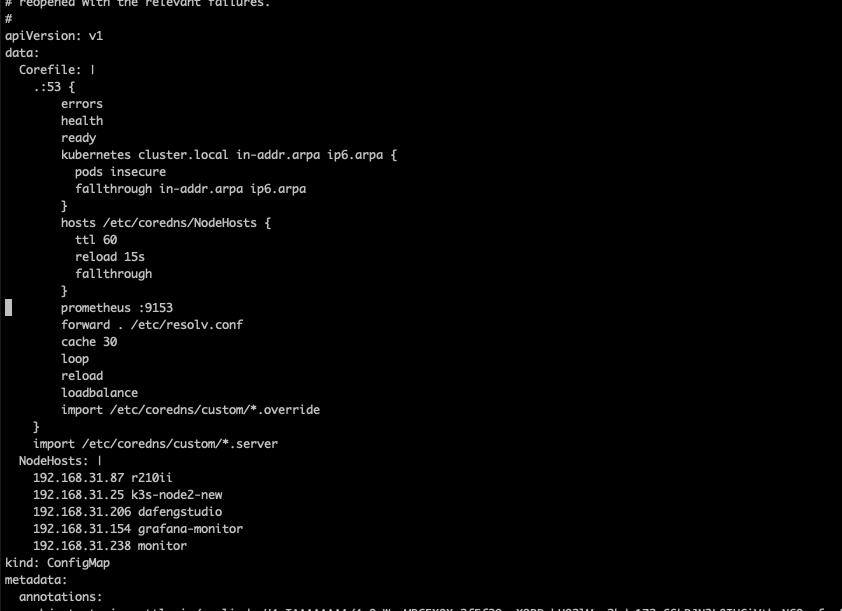
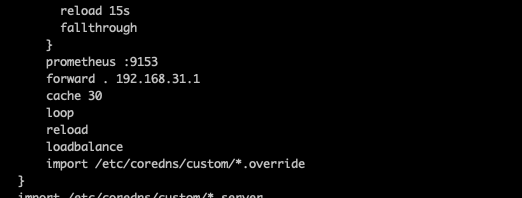
在k8s 上使用
https://www.nginx-cn.net/blog/easy-robust-sso-openid-connect-nginx-ingress-controller/
最后发现 js 模块需要