Deepseek硬件配置选择
基本知识
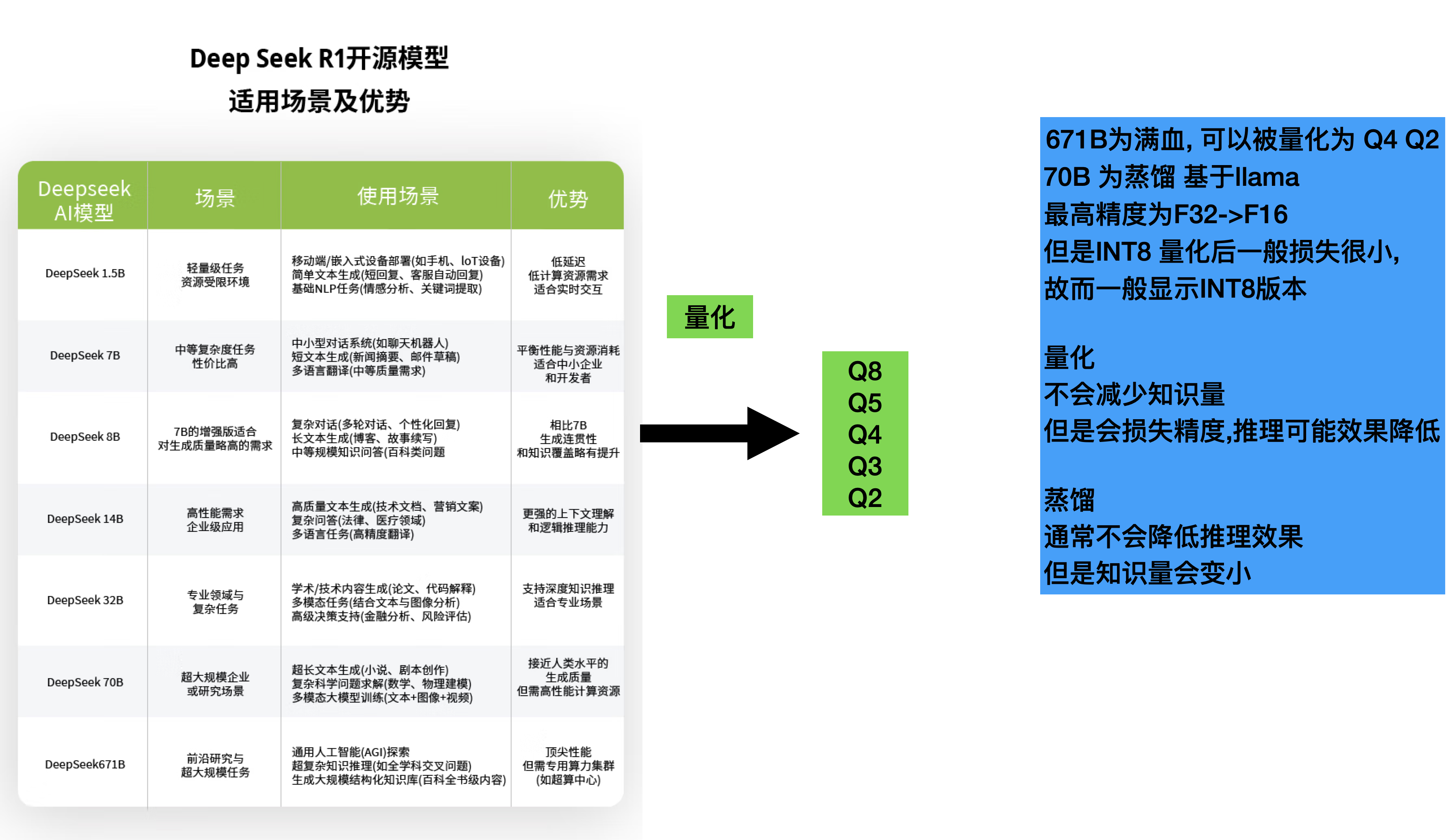
量化蒸馏
(一)满血版:参数巨无霸
满血版 DeepSeek-R1 堪称参数规模上的巨无霸,拥有高达 6710 亿的参数 。这些海量的参数就如同一个庞大的知识储备库,使得模型能够学习到极其丰富和复杂的语言模式、语义信息以及世界知识。在处理复杂任务时,它可以凭借这些参数对各种信息进行深度的分析和理解。 以科学研究领域为例,在处理一篇关于量子物理的复杂论文时,满血版能够快速理解其中晦涩的专业术语、复杂的理论推导以及各种实验数据之间的关系,从而准确地总结论文的核心观点和研究成果。在自然语言生成任务中,无论是创作一篇结构严谨、内容丰富的学术论文,还是构思一个情节跌宕起伏、人物形象鲜明的小说故事,满血版都能轻松应对,展现出强大的语言生成能力。
(二)蒸馏版:参数灵活多样
蒸馏版的参数规模则相对灵活多样,从 1.5B 到 32B 不等,具体的参数数量取决于蒸馏的程度 。蒸馏技术的核心目的是将大模型(教师模型)的知识和能力传递给小模型(学生模型),使小模型在保持较小规模和较低计算成本的同时,尽可能获取大模型的性能,提高模型的泛化能力。 由于参数规模较小,蒸馏版在推理能力上自然略逊于满血版。但在一些资源受限的环境中,如小型企业的服务器或者嵌入式设备中,蒸馏版却能发挥出其独特的优势。在小型企业的客户服务场景中,使用蒸馏版模型搭建的智能客服系统可以快速响应用户的咨询,解答常见问题,提高客户服务的效率,同时又不会对企业的硬件资源造成过大的压力。
(三)量化版:参数与蒸馏版相似
量化版的参数规模和蒸馏版类似,但其独特之处在于通过量化技术进一步压缩了模型大小 。量化技术的原理是降低权重精度,例如将模型参数从 32 位浮点数(FP32)转换为 8 位整数(INT8)。这样一来,模型所占用的存储空间大幅减小,同时在一些支持定点运算的硬件上,推理速度也能得到显著提升。 在移动端设备上,如手机或平板电脑,由于设备的内存和计算资源有限,量化版模型可以轻松部署,实现诸如智能语音助手、图像识别等功能。在智能语音助手应用中,量化版模型能够快速识别用户的语音指令,并给出相应的回答,满足用户在移动场景下的实时交互需求。但这种压缩也并非毫无代价,量化版在精度方面可能会有所牺牲,尤其是在处理复杂任务时,其表现可能不如未量化的版本。
损失程度: 在同等压缩比例下,量化通常比蒸馏的损失更小。 量化主要关注于参数精度,而蒸馏则涉及模型结构的改变和知识的迁移。 适用场景: 量化适用于对推理速度和内存占用有较高要求的场景。 蒸馏适用于需要将大型模型的知识迁移到小型模型的场景。所以优先选择量化版本
Token和字数关系
1 个英文字符 ≈ 0.3 个 token。 1 个中文字符 ≈ 0.6 个 token。
显存占用要求计算逻辑
int8: 模型显存 = 1参数量(Byte) fp16, bf16: 模型显存 = 2参数量(Byte) fp32: 模型显存 = 4*参数量(Byte) int4 4bit,0.5字节 bf16 16位/比特,2字节
- 精度越高 越适用于需要高精度的任务,例如科学计算、复杂模拟等。
- 精度低适用于模糊的任务,如 图像分类、目标检测
- 精度大小影响模型文件大小和显存占用

TOPS(每秒万亿次运算) TOPS(Trillions of Operations Per Second)表示处理器每秒可以执行的整数运算次数,以万亿次为单位。 TFLOPS(每秒万亿次浮点运算) TFLOPS(Tera Floating Point Operations Per Second)表示处理器每秒可以执行的浮点运算次数,以万亿次为单位。
NVlink 和 PCIE 速度差异
带宽: NVLink的带宽远高于PCIe。例如,第四代NVLink的数据传输速度可达到每秒900GB,这远超PCIe 5.0的带宽。 NVLink可以提供5到12倍于PCIe的带宽。 延迟: NVLink的延迟也远低于PCIe。这使得GPU之间可以更快地交换数据,从而提高计算效率。
大约 10倍以上的差距 影响token速度 所以纯CPU能跑和显卡能跑大概至少10倍性能差距
模型的处理逻辑
简化理解两个主要的计算阶段:预填充(Prefill)和解码(Decode)
1. 预填充(Prefill)阶段:
作用: 预填充阶段的主要任务是处理输入的提示(prompt),即你提出的问题。 在这个阶段,模型会将输入的文本转换为内部表示(token),并计算出初始的上下文信息(隐藏状态)。 预填充阶段为后续的解码阶段提供了必要的上下文基础。 计算特点: 预填充阶段的计算量通常与输入提示的长度成正比。 这个阶段可以并行处理输入token,因此在GPU等并行计算设备上效率较高。
2. 解码(Decode)阶段:
作用: 解码阶段的主要任务是根据预填充阶段得到的上下文信息,逐个生成输出的token,即模型的回答。 这是一个自回归的过程,模型会根据已经生成的token来预测下一个token,直到生成完整的回答。 计算特点: 解码阶段是一个串行的过程,每次只能生成一个token,因此并行度较低。 解码阶段的计算量通常与生成回答的长度成正比。
模型层数

模型选择要求
deepseek 各个版本区别

部署方案
纯GPU计算
- 纯jGPU计算, 但是也需要CPU 和 内存配合
- 部署工具:Ollama
纯CPU
- 纯GPU内存计算, 有点显存占用小,确定慢
- 部署工具:Ollama 基于llama.cpp
异构方案(GPU/CPU)
- 自己配置, 需要会调参
- 多层 Ollama 自己配置 卸载层 基于 llama.cpp
- vllm 性能更快
- sglang 性能更快
- LLaMA.cpp
- 清华大学 ktransformers
- 专家卸载:与传统的基于层或 KVCache 卸载(如 llama.cpp 中的)不同,我们将专家计算卸载到 CPU,将 MLA/KVCache 卸载到 GPU,与 DeepSeek 的架构完美对齐,实现最佳效率。
- 英特尔 AMX 优化 – 我们的 AMX 加速内核经过精心调优,运行速度是现有 llama.cpp 实现的数倍。我们计划在清理后开源此内核,并考虑向 llama.cpp 上游贡献代码
硬件选择要求
显存计算

综上
- 显卡显存能 > 模型